Timeception for Complex Action Recognition

@inproceedings{hussein2018timeception,
title = {Timeception for Complex Action Recognition},
author = {Hussein, Noureldien and Gavves, Efstratios and Smeulders, Arnold WM},
booktitle = {CVPR},
year = {2019}
}
Abstract
Problem
This project focuses on the temporal aspect for recognizing human activities in videos; an important visual cue that has long been either disregarded or ill-used. We revisit the conventional definition of an activity and restrict it to Complex Action: a set of one-actions with a weak temporal pattern that serves a specific purpose.
MethodRelated works use spatiotemporal 3D convolutions with fixed kernel size, too rigid to capture the varieties in temporal extents of complex actions, and too short for long-range temporal modeling. In contrast, we use multi-scale temporal convolutions, and we reduce the complexity of 3D convolutions. The outcome is Timeception convolution layers, which reasons about minute-long temporal patterns, a factor of 8 longer than best related works.
ResultsTimeception achieves impressive accuracy in recognizing human activities of Charades. Further, we conduct analysis to demonstrate that Timeception learns long-range temporal dependencies and tolerate temporal extents of complex actions.
Method
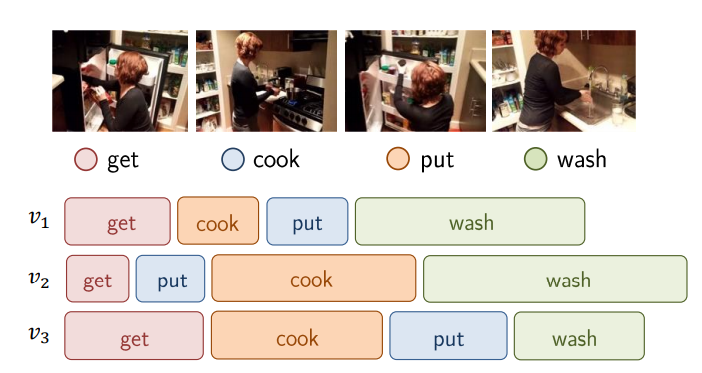
A complex action, e.g.
Cooking a Meal
enjoys few properties:
- composition: consists of several one-actions (Cook, ...)
- order: weak temporal order of one-actions (Get < Wash)
- extent: one-actions vary in their temporal extents
- holistic: it emerges throughout the entire video
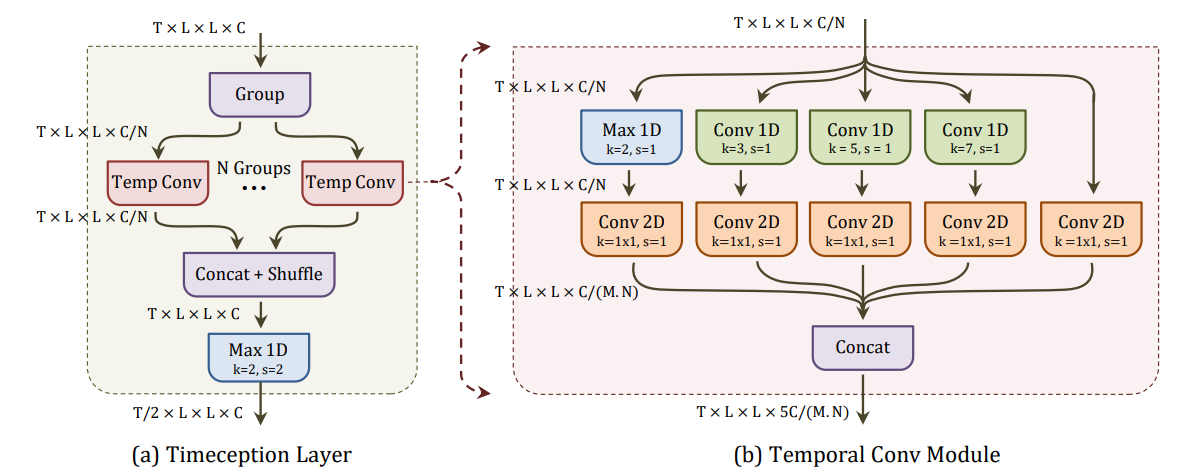
The core component of our method is Timeception layer (left). Simply, it takes as an input the features \bm{X}; corresponding to T timesteps from the previous layer in the network. Then, it splits them into N groups, and temporally convolves each group using temporal convolution module (right). It is novel building block comprising multi-scale temporal-only convolutions to tolerate a variety of temporal extents in a complex action. Timeception makes use of grouped convolutions and channel shuffling, to learn cross-channel correlations, efficiently than 1 \times 1 spatial convolutions.
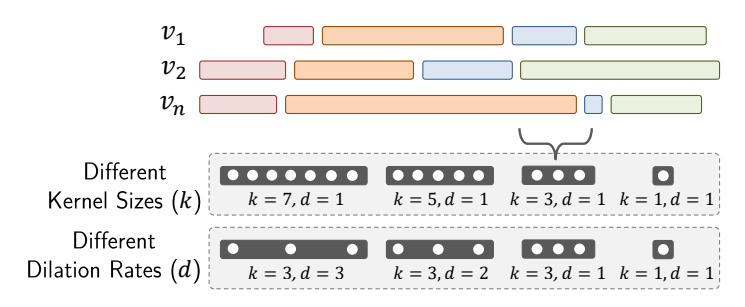
In order to tolerate temporal extents, Timeception uses multi-scale temporal kernels, with two options: i. different kernel sizes k \in \{1, 3, 5, 7 \} and fixed dilation rate d=1. ii. different dilation rates d \in \{ 1, 2, 3 \} and fixed kernel size k=3.
Results
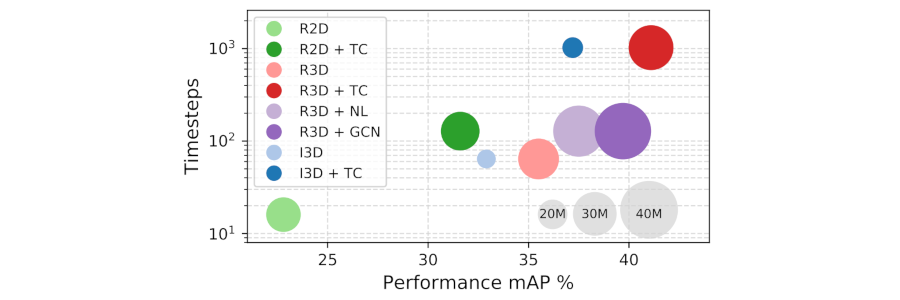
As the figure shows, this is how Timeception layers improves performance (mAP) on Charades, scales up temporal capacity of backbone CNNs while maintaining the overall model size. The same result is observed regrdless the backbone CNN, be it 3D CNN, as in 3D-ResNet and I3D, or 2D CNN, as in 2D-ResNet. The cost of adding new Timeception layers is marginal, compared to related temporal layers.

The learned weights by temporal convolutions of three Timeception layers. Each uses multi-scale convolutions with varying kernel sizes k \in \{3, 5, 7 \}. In bottom layer (1), we notice that long kernels (k=7) captures fine-grained temporal dependencies. But at the top layer (3), the long kernels tend to focus on coarse-grained temporal correlation. The same behavior prevails for the shot (k=3) and medium (k=5) kernels.
| Ours | Method | Backbone | mAP (%) |
|---|---|---|---|
| 2D CNN | ResNet-152 | 22.8 | |
| ✓ | 2D CNN + Timeception | ResNet-152 | 31.6 |
| 3D CNN | I3D | 32.9 | |
| ✓ | 3D CNN + Timeception | I3D | 37.2 |
| 3D CNN | 3D ResNet-101 | 35.5 | |
| 3D CNN + NL | 3D ResNet-101 | 37.5 | |
| 3D CNN + GCN | 3D ResNet-50 | 37.5 | |
| 3D CNN + GCN | 3D ResNet-101 | 39.7 | |
| ✓ | 3D CNN + Timeception | 3D ResNet-101 | 41.1 |
Timeception outperforms related works using the same backbone CNN. It achieves the absolute gain of 8.8% and 4.3% over ResNet and I3D, respectively. More over, using the full capacity of Timeception improves 1.4% over best related work.


