PIC: Permutation Invariant Convolution for Recognizing Long-range Activities

@inproceedings{hussein2020pic,
title = {PIC: Permutation Invariant Convolution for Recognizing Long-range Activities},
author = {Hussein, Noureldien and Gavves, Efstratios and Smeulders, Arnold WM},
booktitle = {arXiv},
year = {2020}
}
Abstract
Problem
Neural operations as convolutions, self-attention, and vector aggregation are the go-to choices for recognizing short-range actions. However, they have three limitations in modeling long-range activities.
MethodThis paper presents PIC, Permutation Invariant Convolution, a novel neural layer to model the temporal structure of long-range activities. It has three desirable properties. i. Unlike standard convolution, PIC is invariant to the temporal permutations of features within its receptive field, qualifying it to model the weak temporal structures. ii. Different from vector aggregation, PIC respects local connectivity, enabling it to learn longrange temporal abstractions using cascaded layers. iii. In contrast to self-attention, PIC uses shared weights, making it more capable of detecting the most discriminant visual evidence across long and noisy videos.
ResultsWe study the three properties of PIC and demonstrate its effectiveness in recognizing the long-range activities of Charades, Breakfast, and MultiThumos.
Method
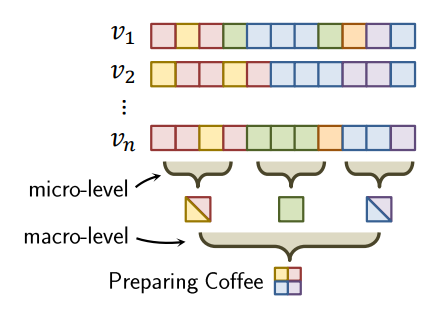
PIC, Permutation Invariant Convolution, recognizes long-range activities using multiple levels of abstractions. On the micro-level of a short segment s1, PIC models the correlation between unit-actions, regardless of their order, repetition or duration. On the macro-level, PIC learns the interactions between segments.
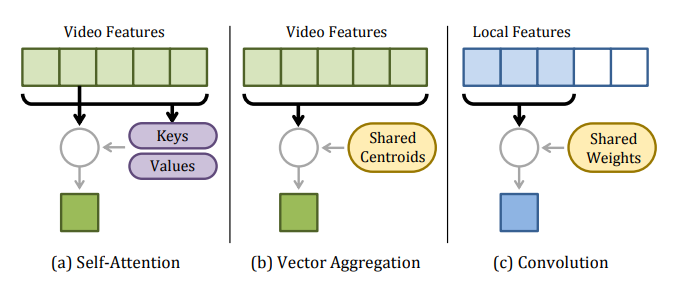
Compared to other temporal modeling layers, PIC has three benefits. i. Temporal locality to learn long-range temporal abstractions using a cascade of layers. ii. Shared weights (i.e. key-value kernels) to detect the discriminant concepts. iii. Invariant to the temporal permutation with in the receptive field, better for modeling weak structures.
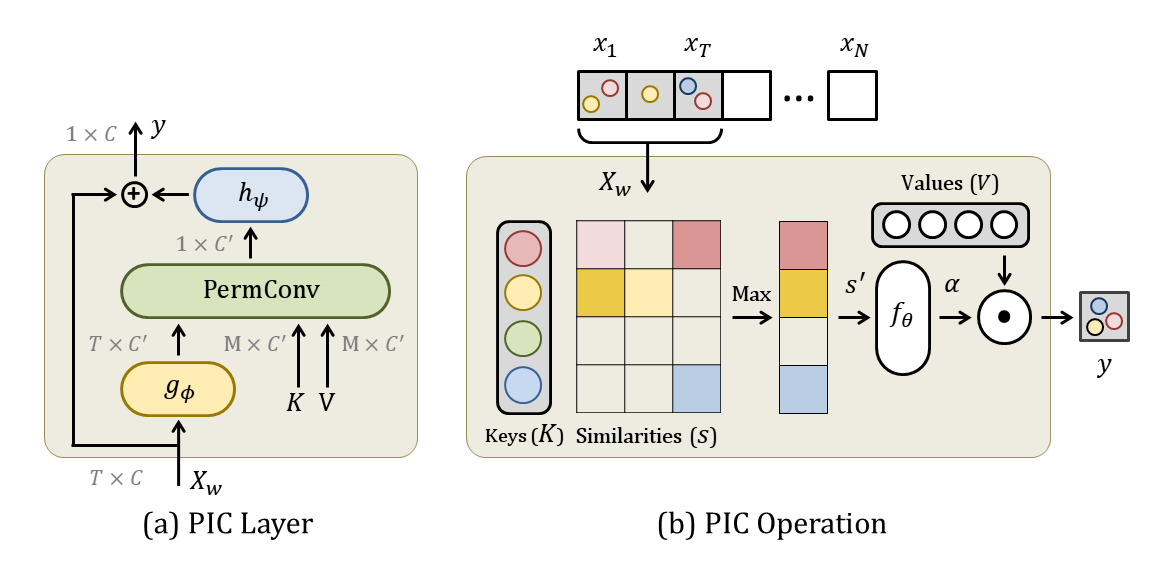
On the left, overview of PIC layer for modeling only the temporal dimension. It has shared kernels (K, V) to learn discriminant concepts. A residual bottleneck is used to reduce computation. On the right, overview of PIC, Permutation Invariant Convolution. Using a pair of Key-Value kernels (K, V), it models the correlation between the visual evidences in a local window of features X_w = \{ x_1, ..., x_T \} irrespective of their the temporal order.
Results

In a cascade of PIC layers, we notice that in the bottom layer, the learned concepts are fine-grained and independent of the activity category. For example, the concept “Pouring” is irrespective of activities “coffee” or “tea”. Also, these concepts can be object-centric as “food box” or action-centric as “cutting”.

On x-axis, the number of stacked layers. While on y-axes, the the efficiency of temporal layers using four metrics: i. CPU feedforward time (milliseconds), ii. model parameters (millions), iii. number of operations (mega FLOPS), and iv. classification accuracy (%). PIC has the best tradeoff between efficiency and effectiveness.
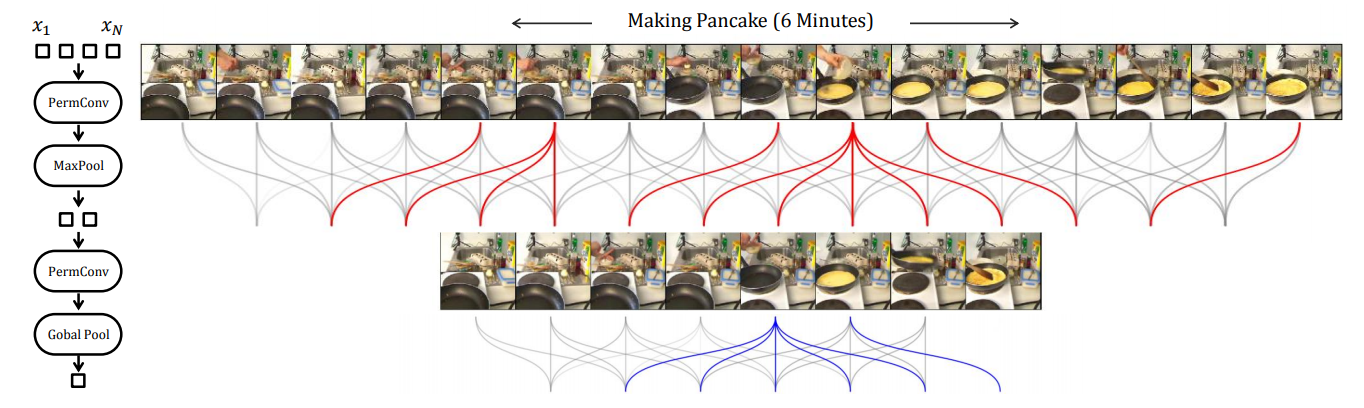
This figure shows 16 frames uniformly sampled from an activity of “Making Pancake”. After one layer, M concept kernels are learned to detect relevant visual evidences. For simplicity, we show the activations of only one kernel, in red.
| Ours | Method | Backbone | mAP (%) |
|---|---|---|---|
| SlowFast | ----- | 42.1 | |
| SlowFast-NL | ----- | 42.5 | |
| 3D CNN | R101 | 35.5 | |
| 3D CNN + Timeception | R101 | 41.1 | |
| ✓ | 3D CNN + PIC | R101 | 42.7 |
| 3D CNN | R101-NL | 41.0 | |
| 3D CNN + Feature Banks | R101-NL | 42.5 | |
| ✓ | 3D CNN + PIC | R101-NL | 43.8 |
When classifying the complex multi-label actions of Charades, PIC layers bring improvements over previous works. Using the full capacity of PIC, it improves 1.3% over best related work.


