TimeGate: Conditional Gating of Segments in Long-range Activities

@inproceedings{hussein2020timegate,
title = {TimeGate: Conditional Gating of Segments in Long-range Activities},
author = {Hussein, Noureldien and Jain, Mihir and Bejnordi, Babak Ehteshami},
booktitle = {arXiv},
year = {2020}
}
Abstract
Problem
When recognizing a long-range activity, exploring the entire video is exhaustive and computationally expensive, as it can span up to a few minutes. Thus, it is of a great importance to sample only the salient parts of the video.
MethodWe propose TimeGate, along with a novel conditional gating module for sampling the most representative segments from a long-range activities. Different from previous sampling methods, as SCSampler, TimeGate has two novelties: First, it enables a differentiable sampling of segments. Consequently, TimeGate is fitted with modern CNNs as single and unified end-to-end model. Second, the sampling is conditioned on both the segments and its context. Thus, making TimeGate better suited for long-range activities, where the importance of a segment heavily depends on the video context.
ResultsWe report results of TimeGate on two benchmarks for long-range activities: Charades and Breakfast, with much reduced computation. In particular, we match the accuracy of I3D by using less than half of the computation.
Method
Top, untrimmed video of short-range action “disc throw”. Based on each segment, you can tell weather is it relevant (green) to the action or not (red). But in complex and long-range activities, middle and bottom, the importance of each segment is conditioned on the video context. The segment “get food from cupboard” is relevant to “cook food” but not to “washing dishes”.

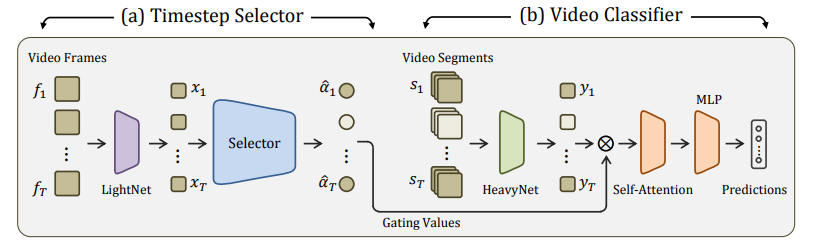
Overview of the proposed model, TimeGate, with two stages. The first stage is the timestep selector, left. Based on a lightweight CNN, LightNet, it learns to select the most relevant timesteps for classifying the video. This selection is conditioned on both the features of timestep and its context. The second stage is the video classifier, right. It depends on heavyweight CNN, HeavyNet, to effectively represent only timesteps selected in the previous stage. Then it temporally models these selected timesteps to arrive at the video-level feature, which is then classified.
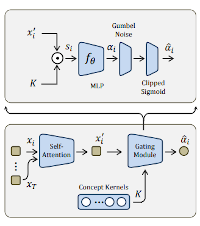
Bottom, the timestep selector learns concept kernels K to represent the most representative visual evidence. Top, the gating module learns to select only a timestep feature xi according to its importance to the current video.
Results
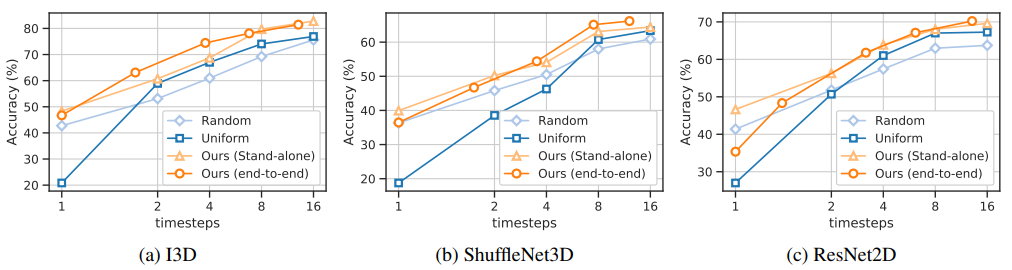
Our stand-alone timestep selector helps improving the performance and reduces the computation of off-the-shelf CNN classifiers – be it 2D/3D heavyweight CNN or even lightweight 3D CNN. More over, if TimeGate is trained end-to-end, the selector learns a better gating to the benefit of the classifier. So, the performance is improved even further.
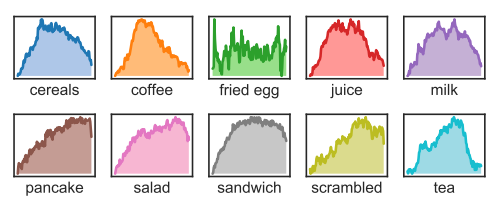
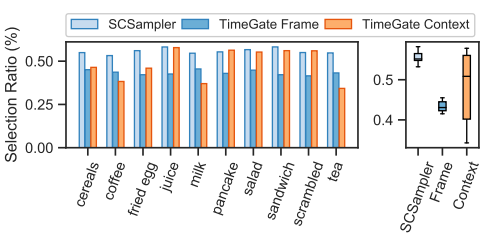
In both the frame-conditioned TimeGate and SCSampler, the ratio of the selected timesteps have small variance across the activity classes of Breakfast. In contrast, in context-conditioned TimeGate, the ratio is highly dependent on the activity. It obtains context-conditional gating.
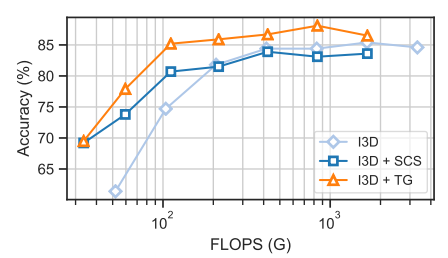
Both TimeGate (TG) and SCSampler (SCS) reduce the computational cost of I3D. Though, TimeGate achieves a better performance than that of SCSampler.

Top, frames corresponding to the selected timesteps by TimGate. Bottom, are those discarded by TimeGate. The shown figures are for three activities: “making sandwich”, “preparing coffee”, and “making pancake”. The general observation is that TimeGate tends to discard the segments with little discriminative visual evidences
Distribution of the gating values for each activity of Breakfast. Some activities are simple, as making “making coffee”. Others are complex, as “making sandwich”.